
L’architecture complexe que nous avons largement détaillée dans les parties précédentes est un perceptron multi-couches (MLP pour Multi Layer Perceptron). C’est l’architecture classique du réseau neuronal. Néanmoins, en fonction du type de données que l’on utilise en entrée des modèles neuronaux (images, signal vocal…), des architectures un peu plus spécifiques ont été mises en place. Pour travailler avec des images par exemple, et être capable de considérer les relations spatiales entre pixels voisins, les réseaux de neurones convolutifs (CNN pour Convolutional Neural Networks) ont été développés. Pour analyser des textes ou des voix par exemple, et être capable de considérer les relations temporelles entre des mots/phrases voisines (on n’utilise pas n’importe quel mot après un autre), les réseaux de neurones récurrents ont été développés (RNN pour Reccurent Neural Networks).
On se concentrera dans cette section sur les réseaux de neurones convolutifs pour traiter les images. Bon, la première question qu’on peut se poser, c’est pourquoi on a eu besoin de mettre en place une architecture particulière pour les images ? Après tout, une image, ça reste un tableau avec des chiffres, non ? Si vous prenez une image très classique, disons celle d’un chat tout mignon, de 32 pixels. Sur une image classique, on parle généralement d’image RGB parce qu’il y a trois canaux de couleurs (Red Green Blue), ce qui permet de rendre les images en couleur visibles comme on a l’habitude de les voir. Sur cette image de chat, il y a donc 32×32 pixels pour un des canaux de couleur (puisqu’une image est carrée) et ça pour les trois canaux R, G et B présents. L’ensemble de l’image est donc composé de 32x32x3=3072 dimensions. Ca fait donc déjà 3072 poids à fixer dans un modèle neuronal si on se place dans une architecture de perceptrons simple (et je ne parle même pas de perceptrons multi-couches….). Hummm, okay ça peut encore le faire. Et si on commence à prendre des images un peu plus larges ? Un peu plus grand par exemple avec des images de 100 pixels ? 30000 dimensions ! Aouch. 250 pixels ? 187500 dimensions… Bon, okay on abandonne ! Vous imaginez fixer plus de 150000 poids dans le modèle neuronal (encore une fois, rien que sur un modèle très simple de perceptron) ?
Les réseaux de neurones convolutifs
Si vous êtes convaincus qu’il faut une architecture particulière pour travailler sur des images, regardons à quoi ressemble une architecture de réseau de neurones convolutifs (vous m’excuserez, c’est une image de chien et pas de chat en entrée…) :
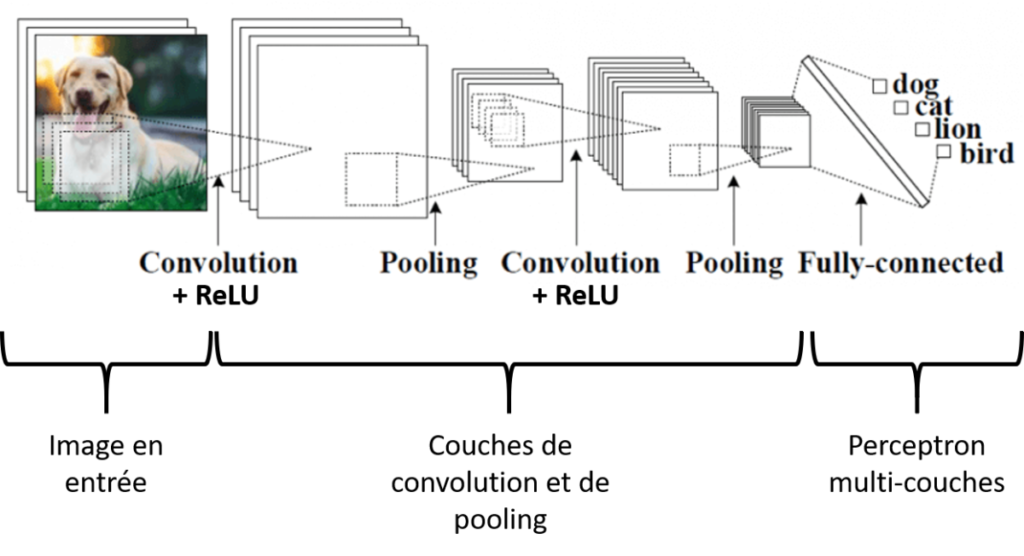
Figure 1. Réseaux de neurones convolutifs
Prenons un cas d’étude relativement classique dans lequel nous aurions besoin de travailler avec des réseaux de neurones sur des images : nous allons chercher à classifier l’animal sur une image d’entrée et il faudra décider si cet animal est un chien, un chat, un lion ou un oiseau. Le réseau de neurones convolutifs présenté dans la figure est constitué de deux grosses briques de base dont une que vous connaissez maintenant ! Dans la première brique, l’algorithme va réaliser des séquences successives de traitement (Convolution – Activation – Pooling) pour simplifier l’image d’entrée en caractéristiques d’intérêt (ce qu’on appelle les « features » en anglais). Les caractéristiques extraites passent ensuite dans une architecture de perceptron multi-couches de façon à aboutir à une image classifiée. La « seule » chose de nouveau ici reste bien la partie Convolution – Activation – Pooling. Les mécanismes d’apprentissage du réseau (forward propagation et backpropagation) restent identiques ou du moins les concepts sont les mêmes donc je ne reviendrai pas dessus. Et c’est pareil pour les solutions pour limiter le sur-apprentissage (régularisation, dropout…), vous savez déjà tout !
Je viens de parler de features, on va s’arrêter brièvement dessus. On a vu que la limite des perceptrons multi-couches pour traiter les images, c’était que le modèle neuronal allait avoir beaucoup trop de poids à paramétrer. Pour limiter ce nombre de poids, on va donc extraire des caractéristiques importantes de l’image, ce qui va permettre de la synthétiser en quelque sorte. Et on pourra par la suite utiliser cette synthèse pour réaliser nos prédictions / classifications. L’utilisation de features n’est pas nouvelle et va au-delà des réseaux de neurones. Dans beaucoup de méthodes de machine learning, lorsque l’on veut travailler sur des images, on en extrait des caractéristiques manuellement (par exemple, on extrait la texture, les frontières…) au préalable de manière à utiliser ces features dans des algorithmes de classification. Comme ces features sont choisies de façon experte, il est raisonnable de penser que les méthodes de classification devraient marcher correctement. Dans le cas des réseaux de neurones convolutifs, l’algorithme trouve tout seul ces features d’intérêt ! C’est lui qui trouve les features les plus à même d’optimiser sa classification. Certaines features pourront nous paraitre pertinentes si nous devions les regarder avec notre œil, d’autres seraient peut-être plus surprenantes. En tout cas, il faut bien comprendre que l’utilisation de réseaux de neurones convolutifs nous soulage de cette étape d’extraction de features dans le sens où ce travail est réalisé en interne par l’algorithme.
Parlons maintenant du passage de l’image au travers du processus Convolution – Activation – Pooling :
- La Convolution: L’étape de convolution est très classique en traitement d’images (cf image ci-dessous) Elle consiste à déplacer un filtre (ou kernel en anglais) en le faisant glisser sur une image et à réaliser une convolution (un produit matriciel) de ce filtre avec l’image sous-jascente. Ce filtre n’est rien d’autre qu’une matrice carrée de poids (et ces poids seront déterminés par la descente de gradient !). Dans l’image ci-dessous, nous faisons face à trois tableaux de pixels (les canaux Red, Green et Blue), avec un filtre (kernel) associé à chacun. Ne faites pas attention aux valeurs 0 en bordure, nous y reviendrons après ! Pour le filtre rouge en haut à gauche de l’image, la valeur 308 est obtenue en faisant le calcul 156-155+153+154 (toutes les autres valeurs étant à 0). Pour le filtre vert, la valeur -498 est obtenue en faisant le calcul -167-166-165 (toutes les autres valeurs étant à 0). Pour le filtre bleu, la valeur 164 est obtenue en faisant le calcul 163-160+161.
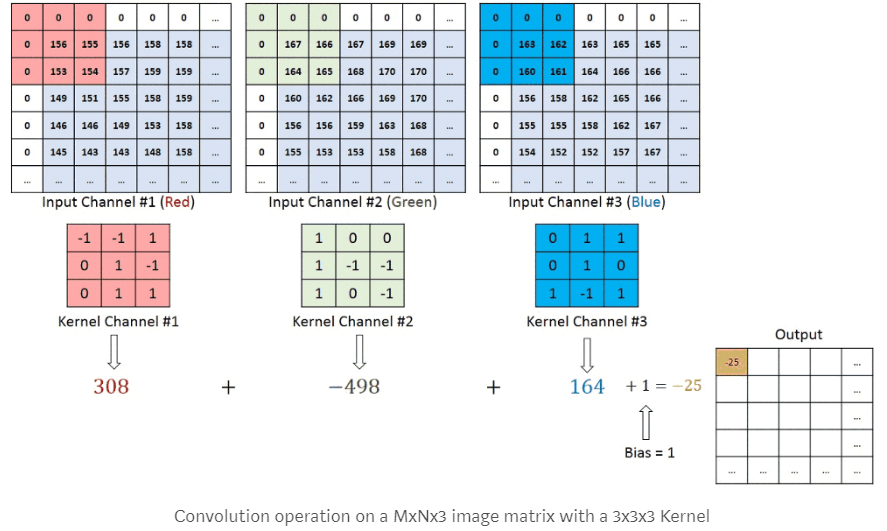
Figure 2. Réseaux de neurones convolutifs – La convolution
On voit que le filtre de taille 3×3 (9 pixels) transforme les valeurs de 9 pixels en une seule valeur. Est-ce que ça veut dire qu’appliquer une convolution va nécessairement réduire la taille d’une image ? Oui ! Sauf si on rajoute des 0 autour de l’image d’origine. Vous pouvez faire le test tout seul mais si vous utiliser une image 5x5x1 (un seul canal pour faire simple) avec un filtre 3×3, vous obtiendrez en sortie une image 3x3x1. Alors que si vous rajoutez un contour d’un pixel de 0 à l’image (comme ce qu’on voit dans la figure au-dessus), vous aurez une image d’origine de 6x6x1. Et si vous faites passer un filtre 3×3, vous aurez une image en sortie de convolution de 5x5x1 ! Ce contour de 0 permet donc de conserver la même taille d’image d’origine, ce qui est souvent intéressant ! Le fait de rajouter des 0 autour de l’image s’appelle le Padding. Avec un padding de 0, aucun contour de 0 n’est rajouté. Avec un padding de 1, un contour de 0 est rajouté. Avec un padding de 2, deux contours de 0 sont rajoutés, et ainsi de suite ! Je vous ai dit plus tôt que lors de la convolution, on faisait glisser le filtre sur toute l’image mais je ne vous ai pas dit de combien de pixels on décalait le filtre au fur et à mesure. Vous pouvez le décaler d’un pixel à la fois ou de plus ! Ce choix de pixels s’appelle le Stride. Avec un stride de 1, le filtre se déplace d’un pixel à la fois. Avec un stride de 2, de deux pixels à la fois. D’une manière générale, on choisit le stride de façon à ce que la taille de l’image en sortie soit un entier et pas un décimal… Avec la formule suivante, vous pourrez savoir la taille de l’image en sortie d’une convolution à partir de la taille de l’image d’entrée (W), la taille du filtre (F), le padding (P) et le stride (S) :
Taille sortie convolution = 1 + \frac {W - F + 2P}{S}
Pour une image d’entrée 5×5, un filtre 3×3, un padding de 0 et un stride de 1, on obtient une image de taille : 1+ (5-3+2*0)/1, soit 3 c’est à dire une Image 3×3
Pour une image d’entrée 5×5, un filtre 3×3, un padding de 1 et un stride de 1, on obtient une image de taille : 1+ (5-3+2*1)/1, soit 5 c’est à dire une Image 5×5
- L’activation: En fait rien de nouveau sous le soleil ! A la suite d’une convolution, on applique souvent une fonction d’activation type ReLU pour rajouter un aspect non linéaire à notre modèle (vous avez vu que la convolution était une combinaison linéaire des valeurs du filtre et de l’image sous le filtre). L’utilisation de la fonction d’activation ReLU permet aussi de ne pas avoir de valeur négative sur l’image en sortie de convolution (je vous rappelle que la fonction ReLU(z)=max(0,z))
- Pooling : Tout ça, c’est bien joli mais si on a des images en sortie de convolution qui font toujours la même taille qu’en entrée, on n’a pas résolu le problème du nombre de poids à paramétrer dans le modèle ! C’est pour ça qu’une séquence de traitement se finit par une étape de Pooling. L’étape de Pooling est une étape de sous échantillonnage qui donc de diminuer la taille de l’image. Dans la figure ci-dessous, on réalise l’étape de Pooling avec un filtre Max de taille 2×2 et un stride de 2 (on choisit souvent la même taille de stride que la taille du filtre). C’est-à-dire qu’on découpe l’image en sortie de convolution en carrés de taille du filtre, et que dans chacun des carrés, on extrait la valeur maximale sous le filtre (on aurait pu utiliser d’autres fonctions que la fonction Max !).
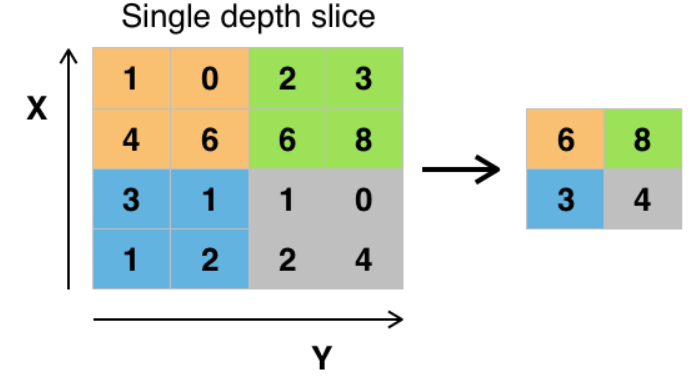
Figure 3. Réseaux de neurones convolutifs – Le Pooling
Comme on peut le voir sur notre exemple de classification d’images par animal, on peut avoir plusieurs séquences Convolution – Activation – Pooling, chacune avec des tailles de filtres différentes ! Souvent la phase d’activation est directement liée à celle de convolution. Et on peut avoir plusieurs phases de Convolution – Activation avant d’avoir une phase de Pooling.
Lorsqu’on décide de mettre en place un réseau de neurones convolutifs pour traiter des images, et lorsque l’on veut avoir une bonne qualité de prédiction/classification, il faut souvent beaucoup (beaucoup beaucoup) d’images. Et clairement, ça peut poser un problème quand on n’a pas moyen d’en acquérir autant. Une des solutions pour aider à pallier ce problème s’appelle l’apprentissage par transfert (ou Transfer Learning en anglais). L’idée est d’utiliser un réseau existant qui a déjà appris sur une très grosse banque d’images (par exemple un réseau de Google) et d’affiner ce réseau pour son cas d’étude propre. On peut effectivement imaginer qu’une très grosse partie des features extraites pour ce réseau existant nous seront utiles pour notre propre réseau (et donc autant l’utiliser !) Ce qu’il nous reste à faire, c’est affiner ce réseau existant en changeant la dernière couche du réseau, le classifieur final (puisqu’on aura effectivement un travail différent que celui qu’avait à faire le réseau au départ, sinon autant utiliser le réseau directement !). Les poids des couches précédentes restent inchangés (on utilise ceux du réseau précédent qui extraient déjà des features intéressantes) et on recalcule seulement les poids associés à la dernière couche du réseau pour avoir un réseau en rapport avec notre étude.
Banques d’images
Pour apprendre à un algorithme à faire une tâche comme par exemple reconnaître un chat, nous avons dit qu’il fallait un très grand nombre d’images. « Aucun problème ! », me direz-vous. « J’ai moi-même quantité de photos de mon chat, cela devrait bien suffire pour apprendre à un modèle ce qu’est un chat ». Deux principaux problèmes se poseront néanmoins. Premièrement, même si vous avez fait de votre chat une vraie star de la photo, la quantité de photos est probablement insuffisante. Deuxièmement, la diversité des photos (chats différents, partie du chat visible sur la photo, environnement autour du chat, plusieurs chats sur la même photo…) est elle aussi probablement trop faible. Le meilleur algorithme que vous puissiez créer serait peut-être bon pour reconnaître votre chat sous toutes ses coutures, mais pourrait également échouer pour le chat du voisin, ou dire que le cheval dans le pré d’en face est un chat. On a déjà parlé de pré-traitement d’images pour augmenter artificiellement la taille d’échantillons (rotation, distorsions…), c’est la « data augmentation ». Mais d’autres solutions existent : les banques d’images.
Les banques d’images, c’est un ensemble d’un grand nombre d’images regroupées en jeux de données d’images par thématique d’usage précise, et qui sont publiques ou non. Ce sont sur ces banques d’images immenses que sont entraînés des modèles très puissants pour, par exemple, la reconnaissance faciale pour déverrouiller son téléphone, ou encore le guidage autonome de voitures. Outre le fait que les images soient en volume et diversité suffisants dans la banque, elles sont également annotées. L’annotation consiste à renseigner dans chaque image la caractéristique que l’on souhaite que l’algorithme puisse reconnaître sur n’importe quelle image. L’annotation est différente selon l’usage. Notons par exemple :
- La classification d’image pour que l’algorithme soit capable de conclure si une image contient ou non un chat. L’annotation des images du jeu d’apprentissage va consister à faire valider par quelqu’un que chaque image mise en entraînement du modèle contient bel et bien un chat
- La reconnaissance d’objets, comme les épis de blé dans un couvert végétal, en vue d’évaluer une des composantes du rendement de la culture. L’utilisateur annotant ce type d’images va devoir tracer le contour de chaque épi qu’il voit, sur chaque photo, afin que l’algorithme comprenne ce qu’est un épi. C’est déjà une autre paire de manches plus compliqué, n’est-ce pas ?
Avec ces deux exemples, je pense que vous commencez à sentir qu’annoter suffisamment de photos (volume et diversité), une à une, est un travail titanesque. C’est pour cette raison que les banques d’images annotées constituent une richesse considérable pour ceux qui les ont créées. Juste pour que vous soyez au courant, il existe des logiciels pour aider à l’annotation. Par exemple, certains logiciels permettent de détecter les contours des formes, ce qui facilite le travail de l’annotateur mais demande quand même du temps et de la main d’œuvre (https://hackernoon.com/the-best-image-annotation-platforms-for-computer-vision-an-honest-review-of-each-dac7f565fea)
Bien que les banques d’images soient très précieuses et parfois jalousement gardées par leurs créateurs, il existe quand même pas mal de banques publiques de qualité et accessibles à tous. Le plus souvent, ces banques « open source » sont constituées par une communauté d’acteurs (chercheurs, entreprises, spécialistes en oiseaux/fleurs/poissons…) et c’est la contribution de tous ces acteurs ensemble qui permet d’atteindre des volumes et une qualité suffisants d’images. Citons quelques-unes de ces bases :
- « MNIST » : il s’agit d’un unique jeu de données, dont les images représentent des chiffres écrits à la main. Ce jeu de données très simple (petites images carrées en nuance de gris…) est idéal pour débuter dans la classification d’images (reconnaître chaque chiffre manuscrit) et peut être utilisé même avec un ordinateur aux performances assez modestes
- « ImageNet » : banque d’images créée par le monde de la recherche (organisation « WordNet », aussi connue pour des bases de données lexicales linguistiques). Le monde végétal y est assez largement représenté, avec cependant une approche qui tient davantage de la botanique que de la production agricole
- « Plant Image Analysis » : banque mise en place par le monde de la recherche pour l’étude des différents organes (notamment les systèmes racinaire et foliaire) de plusieurs plantes communément cultivées
- « Google’s Open Images » : banque mise en place par Google et sur lesquels ont été entraînés des modèles complexes capables de reconnaître et nommer plusieurs objets dans une même image (et pas uniquement de classifier dans une catégorie)
Du fait de leur gratuité et de leur constitution par une communauté, ce type de banques d’images peut parfois contenir des erreurs (mauvaise annotation, qualité d’image très dégradée…). Ces soucis sont cependant assez mineurs au regard du volume d’images référencées et les communautés en charge du maintien de ces banques les remettent régulièrement à jour.
Packages et bibliothèques à utiliser
Comme l’engouement pour l’analyse d’images est très fort en ce moment, de nombreuses méthodes, packages, bibliothèques ont été mises à disposition, et on peut rapidement s’y perdre. Pas d’inquiétude ! Nous allons présenter ici quelques grands packages et bibliothèques de référence avec lesquels on peut déjà réaliser de solides algorithmes. Je parle ici uniquement du cas d’une utilisation dans Python (se renseigner pour leurs équivalents dans d’autres langages). Les voici :
- Packages Python de manipulation et gestion de données (pratique pour les matrices représentant les images) : « Numpy » et « Pandas » sont très couramment utilisés dans ce domaine
- « cv2 » (de son nom actuel dans Python): de son vrai nom « OpenCV », c’est une bibliothèque maintenue par Intel apportant un grand nombre de fonctionnalités pour la manipulation d’images et de vidéos (import, affichage, changement de référentiel de couleur…).
- « Keras » : cette bibliothèque est devenue aujourd’hui incontournable, tout simplement car elle accomplit bien sa mission : rendre bien plus facile d’utilisation le « moteur » qui fait le gros des calculs. Sans rentrer dans le détail, les « moteurs » les plus connus sont « TensorFlow » (développé par Google), « PyTorch » (utilisé chez Facebook) et « CNTK » (développé par Microsoft). Keras vient se fixer « par-dessus » le moteur que l’on a choisi (ne fonctionne pas avec PyTorch), et nous permet de demander les calculs bien plus facilement que si on faisait la demande directement auprès du moteur.
Les outils présentés sont des outils de base; rien n’oblige à s’en servir, et il existe bien d’autres packages et bibliothèques pour faire des opérations spécifiques à un cas donné. Il faut bien comprendre que Keras (ou équivalent) n’est pas qu’une aide à la création de modèles. C’est aussi une formidable communauté de gens qui publient des modèles écrits qu’il ne reste plus qu’à entraîner, ou même des modèles déjà entraînés et prêts à l’emploi (voir l’apprentissage par transfert dont nous avons déjà parlé). Cela permet de tester beaucoup de méthodes différentes et choisir celle qui nous convient le mieux.
Concours Kaggle
Si vous naviguez sur internet, vous trouverez certainement un grand nombre de sites où des noms alléchants tels que « votre premier réseau de neurones en 5min » attireront peut-être votre attention. Mais résistez aux chants des sirènes ; ces tutoriels sont généralement assez légers et reprennent des cas d’études déjà faits et refaits. D’autres tutoriels plus complets sont accessibles, mais pour l’avoir déjà vécu, il est facile de se décourager et de ne pas aller au bout d’un tel tutoriel (données incomplètes, manque de vision sur les étapes à suivre…).
Je vous conseille plutôt de vous intéresser à Kaggle. Il s’agit d’une plateforme sur laquelle se déroulent des compétitions d’analyse de données. Le fonctionnement est simple : l’organisateur (une entreprise, une communauté, un utilisateur…) expose la question à laquelle il aimerait trouver une réponse via la compétition, il fournit un jeu de données (entraînement) permettant d’y répondre, et il fixe les règles (critère de performance pour départager les candidats). Chaque candidat (individuel ou par équipe) construit une solution à la question (sous la forme d’un modèle) à partir du jeu d’entrainement et peut la soumettre sur la plateforme pour évaluation. Chaque candidat est libre de reprendre son modèle s’il juge devoir l’améliorer, puis le soumet une dernière fois avant la fin de la compétition. Le jeu d’évaluation sur lequel seront réellement classés les candidats est tenu secret jusqu’à la date de fin de la compétition (pour éviter le sur-apprentissage), puis le vainqueur est désigné. Les compétitions tournent autour du thème de l’analyse de données, et une part importante de ces compétitions porte sur le traitement d’images Les intérêts de Kaggle sont les suivants :
- Accès à des jeux de données annotés complets
- Réflexion sur des questionnements réels, généralement très diversifiés, ce qui donne un panorama de tout ce qui peut être fait avec le thème d’intérêt (dans notre cas l’analyse d’images)
- Un cadre motivant, avec un projet bien constitué : on a les bonnes données, une explication claire du problème, bref un cap à suivre pour rester concentrés d’un bout à l’autre
- Une communauté très active et motivée pour partager sa progression : des forums animés par les internautes montrent des bouts de code pour telle ou telle opération, partagent leurs idées pour améliorer la compétence globale… bref on n’est jamais perdu sur la marche à suivre
- Des compétitions pour tous les niveaux
Déjà, bravo si vous en êtes arrivés jusque-là ! Derrière les réseaux de neurones, on a pu voir qu’il y avait un certain nombre de concepts, pas tous toujours facile à appréhender. Les réseaux de neurones, on en entend parler de plus en plus parce que les résultats de régression / classification sont assez impressionnants. L’utilisation massive des réseaux de neurones est surtout due à l’augmentation de la capacité de traitement permise par les outils technologiques actuels et par le fait que l’on dispose de plus en plus de données ! Utiliser des réseaux de neurones, ça demande, comme on l’a vu, de régler pas mal d’hyperparamètres. Il y a quand même pas mal de règles de bonne conduite dans la littérature ou en réutilisant des réseaux qui ont bien marché ! Après, c’est à l’utilisateur de bien comprendre ce à quoi servent ces hyperparamètres de manière à les régler de manière intelligente. Un des problèmes qui reste encore d’actualité avec les réseaux de neurones, c’est encore leur effet un peu « black box ». Ce n’est effectivement pas toujours évident de comprendre comment le modèle a appris ou ce qu’il a décidé pour arriver à sa prédiction. Il y a de la recherche active à ce sujet….
Quelques références à regarder !
- Un ensemble de quelques vidéos avec de très belles illustrations : https://www.youtube.com/channel/UCYO_jab_esuFRV4b17AJtAw
- Un bouquin en ligne très détaillé sur les réseaux de neurones : http://neuralnetworksanddeeplearning.com/
- Une étude de la Chaire AgroTIC sur le deep learning et ses usages en agriculture : https://www.agrotic.org/wp-content/uploads/2018/12/2018_ChaireAgroTIC_DeepLearning_VD2.pdf
- Quelques sites webs avec des animations/informations pertinentes :
Soutenez les articles de blog d’Aspexit sur TIPEEE
Un p’tit don pour continuer à proposer du contenu de qualité et à toujours partager et vulgariser les connaissances =) ?